1. Text analysis vs. text mining vs. text analytics
Meistens werden text analysis und text mining im selben Zusammenhang verwendet. Auch wenn oftmals beide Begriffe unterschiedlich verwendet werden so bedeuten sie doch eigentlich dasselbe, nämlich, dass man den Sinn einer Nachricht extrahiert. Daher wird im folgenden nur von text analysis gesprochen.
Aber es gibt einen Unterschied zwischen text analysis und text analytics. Grundsätzlich kann man dabei sagen, dass text analysis qualitative Ergebnisse liefert, wohingegen es bei text analytics mehr um die Quantität geht.
Bei text analysis werden also wichtige Informationen aus der Nachricht herausgelesen. Oder anders formuliert geht es darum, dass trotz der Vielseitigkeiten der menschlichen Sprache trotzdem die Kernaussage herausgefunden werden kann, mit der dann gearbeitet wird. Es können also dann Informationen herausgefiltert werden, wie beispielsweise, ob etwas positiv oder negativ ist oder was das Hauptthema des Textes ist.
Auf der anderen Seite wird bei text analytics werden verschiedene Muster aus einer großen Menge an Nachrichten herausgefiltert, welche dann in Graphen, Tabellen oder Berichten gezeigt werden können. Bei der text analytics geht es also darum Muster und Entwicklungen von numerischen Ergebnissen herauszufinden. Es können also dann Informationen herausgefiltert werden, wie beispielsweise, die Prozentzahl der positiven Bewertungen.
2. Warum text analysis
Machine learning macht es viel effizienter und schneller als manuelles Aufbereiten von Texten. Außerdem sorgt es für eine schnellere Bearbeitung, die außerdem auch kostengünstiger ist, weil viele Stellen wegfallen, bei der aber dennoch nicht gespart werden muss was die Qualität angeht.
Durch text analysis tools spart man viele Arbeitskräfte, die bei anderen wichtigeren Aufgaben innerhalb eines Unternehmens eingesetzt werden können. Außerdem können dadurch Texte rund um die Uhr und zur Echtzeit bearbeitet werden.
Durch Algorithmen werden außerdem Fehler reduziert, die bei manuellem Bearbeiten leicht auftreten können und Daten können viel genauer aufbereitet werden, als dies von Menschen möglich.
3. Machine learning mit text analysis
Grob kann man behaupten, dass ein text-analysis tool aus drei verschiedenen Schritten besteht.
-
Zunächst muss man sich überlegen, welche Daten gesammelt werden sollen, um damit sein Model zu trainieren und testen. Man unterscheidet hierbei zwischen internal data und external data. Unter external data werden Quellen, wie Zeitungen oder Foren bezeichnet und zu der internal data zählen sämtliche Daten, die eine Firma jeden Tag generiert, wie E-Mails, Reports, Chats, Umfragen oder aus Datenbanken oder Product Analytics.
-
Danach müssen die Daten vorbereitet werden, damit das Programm diese versteht. Dieser Schritt wird meistens als data preprocessing bezeichnet.
-
Zum Schluss wird dann ein Machine learning Algorithmus hinzugefügt, welcher sich um die Analyse kümmert. Diesen kann man entweder komplett selber implementieren oder man nimmt sich Libraries zur Hilfe.
4. Natural Language Processing NLP
4.1. Corpus
Unter dem Corpus werden die Daten bezeichnet, die verwendet werden, um das NLP Model zu trainieren, damit dieses menschliche Sprache versteht und damit arbeiten kann.
4.2. Tokenization
Jeder Token ist beim Tokenizing eine sinnvolle Einheit. Wörter, Zeichen, Nummern oder Sonderzeichen sind dabei ein eigener Token, wobei Leerzeichen keine eigenen Token sind.
Tokenization wird vor allem für verschiedene Sprachen gebraucht, weil es in diesen immer unterschiedliche Regeln gibt.
Let us go to the park.
0: Let
1: us
2: go
3: to
4: the
5: park
6: .In diesem Beispiel sah es zwar vielleicht noch danach aus, als könnte man eine normale split() Methode für solche Funktionalitäten verwenden. Allerdings spielt Tokenization besonders eine wichtige Rolle, wenn Besonderheiten einer Sprache richtig dargestellt werden sollen, wie im nächsten Beispiel zu sehen ist:
"Let's go to the U.K.!"
0: "
1: Let
2: 's
3: go
4: to
5: the
6: U.K.
7: !
8: "4.3. Part-of-speech tagging POS-Tagging
Wie der Name schon vermuten lässt, geht es hierbei um das Taggen von Wörtern zu deren zugehörigen Teil der Sprache (Part-of-speech).
Als Teil einer Sprache werden normalerweise Kategorien von Wörtern bezeichnet, die ähnliche grammatikalische Eigenschaften oder Nutzung besitzen. Im deutschen würden hierbei also die verschiedenen Wortarten gemeint sein.
Beim Tagging werden entweder Statistiken angewendet, wie beispielsweise, dass es sehr wahrscheinlich ist, dass nach einem Artikel ein Nomen folgt.
Außerdem gibt es sogenannte rule-based POS-taggers, welche vordefinierte Regeln verwenden, um das Tagging zu vollziehen oder diese Regeln basierend auf dem Corpus erstellen.
Ein Beispiel für POS-Tagging könnte also folgendermaßen aussehen:
I am going to the U.K.
I: Pronoun
am: Verb
going: Verb
to: Part
the: Article
U.K.: Noun4.4. Named Entity Recognition tagging NER-Tagging
Named Entity Recognition ist eine der wichtigsten Säulen von Natural language processing. Dabei werden Entities aus Texten erkannt und anschließend mit einem Tag der zugehörigen Kategorie versehen.
Beispiele für Entities wären also:
PERSON Personen (inklusive fiktionalen Personen)
NORP Nationalitäten oder religiöse oder politische Gruppen
FACILITY Gebäude, Flughäfen, Brücken, Straßen
LOC Orte
PRODUCT Objekte, Fahrzeuge, Essen
LANGUAGE Sprachen4.5. Stemming
Andere häufig durchgeführte Schritte beim Preprocessing von Texten sind das Stemming sowie Lemmatization.
Beim Stemming werden die Suffixe und Prefixe der einzelnen Tokens des Textes mithilfe eines Stemmers in eine Form überführt, welche nur den Wortstamm zurücklässt.
Auch hierbei gibt es entweder die Möglichkeit selber einen Stemmer zu programmieren oder bereits vorgefertigte Stemmer zu verwenden.
Hier sind einige Beispiele fürs Stemming:
Buying ---> buy
unpredictability ---> un + predict + able + ity
un prefix
predict base word
able suffix
ity suffix4.6. Lemmatization
Unter diesem Begriff wird verstanden, dass alle verschiedenen Arten eines Wortes zu dem "root" Verb umgeformt werden.
Der Unterschied zwischen Stemming und Lemmatization ist, dass bei der Lemmatization versucht wird, dass auch der Kontext miteinbezogen wird. Wörter haben oftmals verschiedene Bedeutungen, je nachdem in welchem Kontext man sie verwendet und können sich dabei häufig sogar von ihrer Wortart unterscheiden.
Dennoch sind Stemmer leichter zu implementieren und laufen schneller und bei vielen Applikationen ist die höhere Genauigkeit auch vernachlässigbar.
Beispiele hierfür sind:
better ---> good
walking ---> walk
walked ---> walk
walks ---> walk
meeting ---> meet (wenn es als Verb gebraucht wird)4.7. Parsing
Es gibt zwei verschiedene Arten von Parsing. Dependency parsing und constituency parsing. Parsing könnte man so beschreiben, dass es eine Art ist um einen Satz auseinanderzuteilen, um die Struktur des Satzes zu verstehen.
4.7.1. Dependency parsing
Wie der Name schon sagt, geht es beim dependency parsing darum, dass die Struktur eines Satzes durch die Abhängigkeiten der Wörter verstanden wird. Die Idee von Abhängigkeiten ist, dass Wörter in einem Satz über Verknüpfungen miteinander verbunden sind. Beim dependency parsing werden die Hauptwörter eines Satzes herausgefunden und anschließend Wörter gesucht, die in Verbindung mit diesen stehen und deren Bedeutung verändern.
sees
|
+--------------+
subject | | object
| |
John Bill4.7.2. Constituency parsing
Bei diesem werden Sätze in Phrasen, oder seperate constitutents, geteilt. Das bedeutet, dass man beim constituency parsing im Gegensatz zum dependency parsing, wo man Beziehungen zwischen den Wörtern bekommt, man die Sätze gruppieren kann. Dies hilft also, um die Struktur von Sätzen zu zeigen. Der Nachteil hierbei ist, dass es keinen Context gibt bei der Grammatik, dafür kann man aber gut nachweisen, ob ein Satz grammatikalisch korrekt oder inkorrekt ist.
Sentence
|
+-------------+------------+
| |
Noun Phrase Verb Phrase
| |
John +-------+--------+
| |
Verb Noun Phrase
| |
sees Bill4.8. Stopwords
Unter Stopwords werden Wörter verstanden, welche zwar häufig vorkommen, aber nicht wirklich viel zum Informationsgehalt eines Satzes beitragen.
Beispiele in der deutschen Sprache wären:
der
und
aber
mit
oder4.9. Vectorization
Systeme können durch Machine Learning Dinge voraussagen, basierend auf vorherigen Eingaben. Diese Systeme benötigen Trainingsdaten, um die Präzision davon zu steigern. Wenn man also sein System trainieren möchte benötigt man eine Darstellungsform, die auch Maschinen verstehen können. Hierbei kommen Vektoren zum Einsatz. Durch die Vektoren kann das System dann die wichtigsten Informationen extrahieren und daraus lernen.
4.10. Skalarprodukt
Beim Natural Language Processing benötigt man sehr oft das sogenannte Skalarprodukt. Dieses kann auch als inneres Produkt oder Punktprodukt bezeichnet werden.
Das Skalarprodukt ordnet zwei Vektoren eine Zahl zu.
Ein Skalarprodukt berechnet man wie folgt:
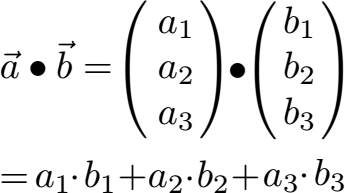
4.11. Kreuzprodukt
Das Kreuzprodukt unterscheidet sich vom Skalarprodukt, indem beim Kreuzprodukt von zwei Vektoren das Ergebnis ebenfalls wieder ein Vektor ist.
Das Kreuzprodukt berechnet man, wie der Name schon vermuten lässt, indem man die Werte der Vektoren überkreuzt zusammenrechnet.
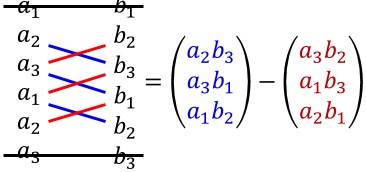
4.12. Bag of Words (BOW)
Es gibt hierzu viele Ansätze aber der berühmteste ist die sogenannte Bag of Words Vectorization. Es ist eine der leichtesten Techniken um Text numerisch zu repräsentieren.
Dabei wird zunächst jedes Wort, welches im Corpus vorkommt als sogenanntes Vokabular gespeichert. Danach wird jeder Satz durch 0en und 1en dargestellt, je nachdem ob das Wort im Vokabular existiert oder nicht.
Dies ist ein Bag of Words Beispiel.
Das 0
Dies 1
ist 1
ein 1
eine 0
Bag 1
of 1
Words 1
Beispiel 1
Example 0Um die Überlappungen von Bag of Words zu berechnen, nutzt man das Skalarprodukt der beiden Vektoren von Sätzen, die man vergleichen will. Bei diesem Skalarprodukt kommt dann immer ein Wert (Skalar) als Ergebnis heraus.
4.13. Bag of n-grams
Ein Bag of n-grams ist ziemlich ähnlich zu einem Bag of Words. Allerdings wird bei einem Bag of n-grams ein Text als eine unsortierte Collection von n-grams dargestellt.
In dem Bag of n-grams wird dann die Anzahl, wie oft ein n-gram vorkommt gespeichert.
Ein n-gram ist eine Sammlung von n aufeinander folgender Wörter. Wenn das n = 2 ist, spricht man von einem bigram, wenn n = 3 ist von einem trigram und so weiter.
Somit würde unser vorheriges Beispiel als bigram folgendermaßen aussehen:
Dies ist ein Bag of Words Beispiel.
1: <start> Dies
2: Dies ist
3: ist ein
4: ein Bag
5: Bag of
6: of Words
7: Words Beispiel
8: Beispiel <end>4.14. Vector spaces
Ein Vector space ist die Sammlung von allen möglichen Vektoren, die in diesem Raum vorhanden sein dürfen.
4.15. Term Frequency times Inverse Document Frequency (TF-IDF)
Eine weitere Repräsentation von Texten in Vektoren, kann mach erzielen, indem man die Vorkommen der Wörter in Sätzen zählt.
Der bekannteste und einfachste Weg um dies zu erledigen ist, indem man TF-IDF verwendet.
TF steht hierbei für Term Frequency. Dabei rechnet man die Anzahl eines Terms, der in einem Dokument vorkommt / Anzahl der Terme insgesamt.
IDF ist der log(N/n), wobei N die Anzahl der Dokumente ist und n die Anzahl des Terms, wie oft er vorkommt.
Wenn die IDF also hoch ist, bedeutet dies, dass das Wort eher seltener in Sätzen vorkommt. Außerdem können auf diese Weise auch Spamwörter weniger Beachtung geschenkt werden.
Ein Beispiel hierfür wäre der Satz This is a beautiful day. Bei dem Wort day ist der Count besonders hoch, weil das Wort selten vorkommt und so wird angenommen, dass dieses wichtig für die Bedeutung des Satzes ist.
Term Count
This 1
is 1
a 1
beautiful 2
day 54.16. Zipfsches Gesetz
Anfang des 20. Jahrhunderts erkannte der Stenograf Jean-Baptiste Estoup ein Muster beim Vorkommen von Dokumenten und er rechnete sich selbst diese aus. In den 1930ern nutzte der amerikanische Linguist George Kingsley Zipf diese Beobachtungen und formulierte ein Gesetz dazu.
Bei dem Modell des Zipfschen Gesetzes kann man bei bestimmten Größen, die in eine Rangfolge gebracht werden, deren Wert aus ihrem Rang abschätzen.
Vereinfacht besagt das Zipfsche Gesetz, dass wenn die Elemente einer Menge nach ihrer Häufigkeit geordnet werden, ist die Wahrscheinlichkeit ihres Auftretens umgekehrt proportional zum Platz auf der Häufigkeitsliste.
Das Zipfsche Gesetz wird benötigt, wenn man beispielsweise folgendes Szenario hat.
Von 1.000.000 Wörtern gibt es
Apfel: 1 mal
Birne: 10 malWenn man die Häufigkeit dieser vergleicht, würde man davon ausgehen, dass Birne viel öfter vorkommt als Apfel, weil die Anzahl dieses Worts eine Exponenz von der Anzahl des Wortes Apfel ist. Deswegen besagt das Zipfsche Gesetz, dass man diese Häufigkeiten noch logarithmieren sollte. Danach kommt als Ergebnis raus, dass diese Wörter beide nicht wirklich oft vorkommen.
4.17. Word2Vec
Word2Vec ist das berühmteste Model für Word Embedding.
Unter Word Embedding wird verstanden, dass Texte in denen Wörter dieselbe Bedeutung haben zusammen repräsentiert werden. Es werden also sozusagen alle Wörter in einem Koordinatensystem dargestellt, wobei Wörter, die zusammen gehören, nah beieinander sind.
Word2Vec nimmt einen großen Corpus an Text und produziert daraus einen Vektor mit den einzigartigen Wörtern, die ähnlich zueinander sind. Es ist sehr berühmt dafür, dass demonstriert werden kann, wie Wörter miteinander verbunden sind.
Ein Beispiel hierfür wäre, dass man erfährt, dass sich Mann zu Frau verhält, wie sich Onkel zu Tante verhält.
4.18. NLP und NLU Tools
4.18.1. NLTK
Das Natural Language Toolkit (kurz NLTK) ist wahrscheinlich die berühmteste Python library für natural language processing. Sie besitzt über 50 Ressourcen für das Bearbeiten von Corpora.
Außerdem gibt es viele eingebaute Libraries für das Analysieren eines Textes, wie die Klassifikation, Tokenization, Stemming, Tagging, Parsing und Semantic reasoning.
4.18.2. SpaCy
SpaCy ist ebenfalls eine sehr berühmte Bibliothek für Python. SpaCy beschreibt sich selbst als "Industrial-Strength Natural Language Processing" und unterstützt über 64 Sprachen.
SpaCy hat nur einen POS-Tagging-Algorithmus und pro Sprache nur einen Named-Entity-Recognizer, was den Vorteil hat, dass es nicht voller unnötiger Features ist und sich nur auf ein paar wichtige Funktionalitäten konzentriert.
4.18.3. TensorFlow
TensorFlow wird von Google betrieben und ist bei weitem die meist verwendete Library für Deep Learning.
Außerdem ist die Plattform Open-Source.
4.18.4. Keras
Keras ist eine Deep Learning Plattform, die in Python geschrieben ist. Sie wurde designed um schnelle Iterationen und schnelles Ausprobieren mit deep neural networks zu ermöglichen.
Außerdem bietet Keras ein Interface zu deep neural networks an, welche dann beispielsweise auf TensorFlow, Theano oder anderen Backends laufen können.
4.18.5. CoreNLP
Das CoreNLP Projekt von Stanford ist ein NLP toolkit, welches zwar in Java geschrieben wurde aber auch in anderen Sprachen verwendet werden kann, die auf der JVM Plattform sind.
4.18.6. Gensim
Gensim ist eine Open-Source Library für Python, mit der man semantische NLP Modelle trainieren kann.
Außerdem ist Gensim Plattform unabhängig und läuft auf jedem Betriebssystem.
4.18.7. TextBlob
TextBlob ist eine Python Library für das Bearbeiten von Texten.
4.18.8. FastText
FastText ist eine Open-Source Library, die es Benutzern erlaubt text representations und text classifier zu verwenden.
4.19. Welche Techniken verwenden die Programme
4.19.1. Rasa
In Rasa kann man nachverfolgen, welche Schritte gemacht werden, indem man in config.yml File navigiert und sich dort die pipeline anzeigen lässt.
pipeline:
# See https://rasa.com/docs/rasa/tuning-your-model for more information.
- name: WhitespaceTokenizer
- name: RegexFeaturizer
- name: LexicalSyntacticFeaturizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 100
constrain_similarities: true
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
constrain_similarities: true
- name: FallbackClassifier
threshold: 0.3
ambiguity_threshold: 0.1Genauere Informationen zu den Komponenten, die bei Rasa verwendet werden kann man unter diesem Link nachlesen.
5. Quellen
Bhargav Srinivasa-Desikan: Natural Language Processing and Computational Linguistics: A practical guide to text analysis with Python, Gensim, spaCy, and Keras ISBN: 178883853X
Hobson Lane: Natural Language Processing in Action: Understanding, analyzing, and generating text with Python ISBN: 1617294632